LLMInference
How Gemma 4’s Built-In Draft Models Change Speculative Decoding
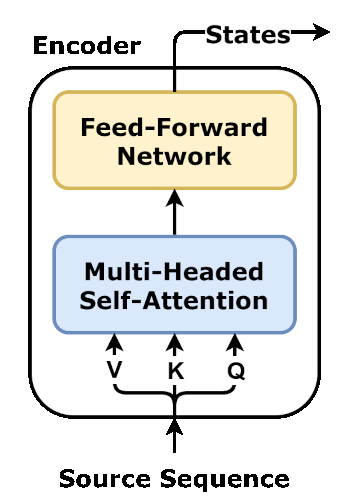
Gemma 4 ships Multi-Token Prediction and paired draft models as a first-class feature — removing the friction of finding, matching, and deploying separate drafters.
Read on LinkedIn